In statistics, linear regression is an approach for modeling the relationship between a scalar dependent variable y and one or more explanatory variables (or independent variables) denoted X. The case of one explanatory variable (independent variable) is called simple linear regression.

Linear regression attempts to model the relationship between two variables by fitting a linear equation to observed data. One variable is considered to be an explanatory variable, and the other is considered to be a dependent variable. For example, a modeler might want to relate the weights of individuals to their heights using a linear regression model.
Before attempting to fit a linear model to observed data, a modeler should first determine whether or not there is a relationship between the variables of interest. This does not necessarily imply that one variable causes the other (for example, higher SAT scores do not cause higher college grades), but that there is some significant association between the two variables. A scatterplot can be a helpful tool in determining the strength of the relationship between two variables. If there appears to be no association between the proposed explanatory and dependent variables (i.e., the scatterplot does not indicate any increasing or decreasing trends), then fitting a linear regression model to the data probably will not provide a useful model. A valuable numerical measure of association between two variables is the correlation coefficient, which is a value between -1 and 1 indicating the strength of the association of the observed data for the two variables.
A linear regression line has an equation of the form Y = a + bX, where X is the explanatory variable and Y is the dependent variable. The slope of the line is b, and a is the intercept (the value of y when x = 0).
There are several linear regression analyses available to the researcher.
• Simple linear regression
1 dependent variable (interval or ratio), 1 independent variable (interval or ratio or dichotomous)
• Multiple linear regression
1 dependent variable (interval or ratio) , 2+ independent variables (interval or ratio or dichotomous)
• Logistic regression
1 dependent variable (binary), 2+ independent variable(s) (interval or ratio or dichotomous)
• Ordinal regression
1 dependent variable (ordinal), 1+ independent variable(s) (nominal or dichotomous)
• Multinominal regression
1 dependent variable (nominal), 1+ independent variable(s) (interval or ratio or dichotomous)
• Discriminant analysis
1 dependent variable (nominal), 1+ independent variable(s) (interval or ratio)
When selecting the model for the analysis another important consideration is the model fitting. Adding independent variables to a linear regression model will always increase the explained variance of the model (typically expressed as R²). However adding more and more variables to the model makes it inefficient and over-fitting occurs. Occam's razor describes the problem extremely well – a model should be as simple as possible but not simpler. Statistically, if the model includes a large number of variables the probability increases that the variables test statistically significant out of random effects.
The second concern of regression analysis is under fitting. This means that the regression analysis' estimates are biased. Under-fitting occurs when including an additional independent variable in the model will reduce the effect strength of the independent variable(s). Mostly under fitting happens when linear regression is used to prove a cause-effect relationship that is not there. This might be due to researcher's empirical pragmatism or the lack of a sound theoretical basis for the model.




Linear regression attempts to model the relationship between two variables by fitting a linear equation to observed data. One variable is considered to be an explanatory variable, and the other is considered to be a dependent variable. For example, a modeler might want to relate the weights of individuals to their heights using a linear regression model.
Before attempting to fit a linear model to observed data, a modeler should first determine whether or not there is a relationship between the variables of interest. This does not necessarily imply that one variable causes the other (for example, higher SAT scores do not cause higher college grades), but that there is some significant association between the two variables. A scatterplot can be a helpful tool in determining the strength of the relationship between two variables. If there appears to be no association between the proposed explanatory and dependent variables (i.e., the scatterplot does not indicate any increasing or decreasing trends), then fitting a linear regression model to the data probably will not provide a useful model. A valuable numerical measure of association between two variables is the correlation coefficient, which is a value between -1 and 1 indicating the strength of the association of the observed data for the two variables.
A linear regression line has an equation of the form Y = a + bX, where X is the explanatory variable and Y is the dependent variable. The slope of the line is b, and a is the intercept (the value of y when x = 0).
There are several linear regression analyses available to the researcher.
• Simple linear regression
1 dependent variable (interval or ratio), 1 independent variable (interval or ratio or dichotomous)
• Multiple linear regression
1 dependent variable (interval or ratio) , 2+ independent variables (interval or ratio or dichotomous)
• Logistic regression
1 dependent variable (binary), 2+ independent variable(s) (interval or ratio or dichotomous)
• Ordinal regression
1 dependent variable (ordinal), 1+ independent variable(s) (nominal or dichotomous)
• Multinominal regression
1 dependent variable (nominal), 1+ independent variable(s) (interval or ratio or dichotomous)
• Discriminant analysis
1 dependent variable (nominal), 1+ independent variable(s) (interval or ratio)
When selecting the model for the analysis another important consideration is the model fitting. Adding independent variables to a linear regression model will always increase the explained variance of the model (typically expressed as R²). However adding more and more variables to the model makes it inefficient and over-fitting occurs. Occam's razor describes the problem extremely well – a model should be as simple as possible but not simpler. Statistically, if the model includes a large number of variables the probability increases that the variables test statistically significant out of random effects.
The second concern of regression analysis is under fitting. This means that the regression analysis' estimates are biased. Under-fitting occurs when including an additional independent variable in the model will reduce the effect strength of the independent variable(s). Mostly under fitting happens when linear regression is used to prove a cause-effect relationship that is not there. This might be due to researcher's empirical pragmatism or the lack of a sound theoretical basis for the model.
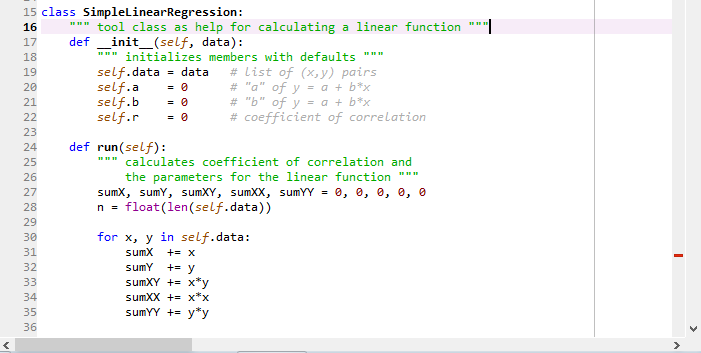
Linear regression in Python:
what is the problem? where is the data? i really do not care about Thomas Lehman's program. awful
ReplyDelete